Deriving the Nyquist theorem from the Eigenlearning framework
If you’re an AV nerd, you’re probably familiar with the number 44,100:
In middle school, when I first started poking around FL Studio, I wanted to understand where this number came from. I immediately came across the Nyquist-Shannon theorem. Very roughly, I understood it to state that if you want to recover a frequency from discrete samples, your sampling rate has got to be at least . Human hearing goes up to 20 kHz, so the sampling rate needs to be at least 40 kHz. In 1979 Sony decided to go with 44.1 kHz to have a bit of practical headroom, setting the industry standard. I remember wishing I could understand how it’s possible to perfectly recover a continuous analog signal from only discrete samples — isn’t that an infinite amount of compression?? Unfortunately, the Wikipedia article was impenetrable to me at the time, so I decided I didn’t need to know.
Recently I realized that this signal recovery problem is essentially a learning problem: we want to recover a continuous target from finite samples. The eigenlearning framework, our theory of high-dimensional linear regression, should apply directly.
This is really interesting to me because it’s a clear illustration of the duality between learning and compression. In the linear case, the duality is well-understood; this blog post aims to make it explicit.
Fair warning: the technical parts of this blog post assume an understanding of linear algebra and some rough familiarity with the theory of linear regression.
tl;dr
The Nyquist-Shannon theorem is just a special case of eigenlearning under a “passband” prior. If we know a priori that the target function lies in a given -dimensional subspace of the full Hilbert space, then we can perfectly reconstruct it with only samples using linear regression. Things get even nicer if the samples form a uniform lattice in the domain: then the data kernel becomes diagonal and we can solve the interpolator without expensive kernel inverses. This gives us the celebrated Whittaker-Shannon interpolation formula.
Disclaimer: Throughout this post I focus on recovering periodic signals, because this problem is easy to understand. However, Nyquist-Shannon is generally about aperiodic signals. So all the results here are finite-period analogs of the general results: we get Dirichlet kernels instead of sinc kernels, we get a fixed number of samples instead of a finite sampling rate, yada yada. In principle, you can recover the general result by taking the period and handling the associated mathematical intricacies, but I don’t bother thinking about that because I think uncountable infinity is fake and bad. (…skill issue.) Anyways, if you’re curious about this, you might find something useful in this conversation.
What the Nyquist-Shannon theorem says
Nyquist-Shannon concerns the following question: “When is it possible to fully reconstruct an unknown periodic signal from finitely many discrete samples?”
In general, you’d expect the answer to be “never” — a continuous signal has infinitely many degrees of freedom, and samples can only constrain of them. However, the story changes if we know something extra about the target function up front. Nyquist-Shannon considers the following constraint: suppose the frequencies in the target signal are all contained in a frequency band of bandwidth . In this case is lossless discretization possible?
Yes, it is. Here’s how.
- Suppose is a periodic scalar signal with period . If its Fourier series coefficients vanish outside a passband of width (excepting the constant DC mode ), then lossless discretization is possible if we take at least samples of . (This is Nyquist’s 1928 result.)
- If these samples comprise a uniformly-spaced lattice in time, then we can reconstruct using the following formula. (This is Shannon’s 1949 result, based partly on E. T. Whittaker’s 1915 result.)
Stay tuned — we’ll soon understand both these results in terms of kernel regression and our eigenlearning framework.
This animation illustrates the idea. Here, the sampling is always uniform but the number of samples is initially insufficient. As the number of samples increases, the recovered frequency band gets wider in the frequency domain (red), and the reconstruction (gold) improves. At the end, there are enough samples for perfect reconstruction. 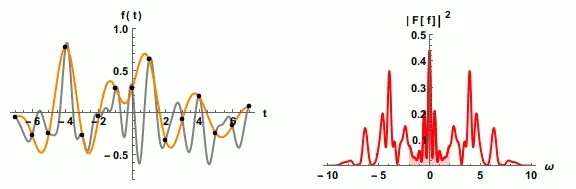
What eigenlearning says
Eigenlearning concerns the following question: “On average, how well can we reconstruct an unknown function from finitely many discrete samples using kernel ridge regression?”
Since kernel regression (KR) is just linear regression in a high-dimensional feature space, eigenlearning is really just about understanding the generalization behavior of linear regression. It describes1 estimators of the following form:
where is any test input, contains the training inputs , and is a pre-specified kernel function. Then and are -dimensional vectors, and is an matrix. For the linear kernel , this reduces to ordinary linear regression.
Here is how I’d describe the core result of eigenlearning:
- The kernel’s eigendecomposition, , specifies an orthonormal set of basis functions, , and corresponding “spectral weights” .2 These are the core ingredients that describe how well the kernel learns.
- Here, is the rank of the kernel. For common kernel functions like Gaussian RBF or Laplace, . If is finite, then only the target functions that lie entirely within the span of the eigenbasis are perfectly learned as .
- It is useful to frame KR as “trying to reconstruct the components of the target function in the kernel eigenbasis.”
- Concretely, the decomposition is , where are the target coefficients, and is the part of orthogonal to (unlearnable).
- Given samples of the target function, KR more readily reconstructs the with the largest corresponding eigenvalues . As increases, KR begins to resolve eigencomponents with increasingly small .
- In this sense, the eigenvalues specify a spectral bias of the learning algorithm; they specify what types of functions KR prefers to construct its estimators out of. Typically, these preferred functions enjoy some smoothness or low-degree-ness.
- The average fraction of basis function actually recovered by KR is given by , where satisfies if (overparameterized), and otherwise.
This paints a clear picture of average-case learning in linear regression: KR fits samples using (roughly) its top eigenfunctions.
How eigenlearning yields Nyquist-Shannon
Comparing the first sentences of each of the preceding sections should be a strong hint that Nyquist-Shannon will fall out of eigenlearning.
In Nyquist-Shannon our function space consists only of functions with period (WLOG). The dimension of the space is countably infinite; the Fourier basis is natural. Now we further assume that the target function is bandlimited: it contains no more than distinct integer frequencies. Each frequency has a and component (or alternatively, an amplitude and a phase) which are independent. There may be a DC offset too (i.e., a constant mode) which has no phase. Therefore there are exactly target coefficients we’ve gotta learn, and we can (in principle) constrain them all if we have at least samples.
Ok, this heuristic argument is nice, but how do we actually reconstruct the signal? Well, let’s just construct a kernel and run KR. To specify a kernel, we need to specify its eigenfunctions and corresponding eigenvalues. We know that the target function may have some DC component, and the rest is contained entirely within the -dimensional space of sinusoids within the given frequency band, so let’s make these the top eigenfunctions. Let’s set their eigenvalues to all be 1 (though it doesn’t really matter what the eigenvalues are, as long as they’re positive). This gives
where is the set of positive integer frequencies in the passband. Then, according to eigenlearning:
- the rank of the kernel is
- so
- So therefore , and the estimation variance is zero. (See side quest 1.)
As a result, the target signal is almost always perfectly reconstructed using KR — we don’t need uniformly-spaced samples! This guarantee is the first part of Nyquist-Shannon.
Unfortunately, KR is annoying because evaluating the estimator typically requires inverting a large kernel matrix. Can we get around this if we sample in a special way? The answer is yes; this is the second part of Nyquist-Shannon. We will show that the estimator becomes explicit and inverse-free if the samples are taken from a uniform lattice.
Proof by direct computation. Let’s just evaluate the KR estimator with the kernel we just constructed. For simplicity, let’s assume the frequencies are in the band . (To show that we can make this assumption WLOG, see side quest 2.) Then, using a trig identity, we find that the kernel is the Dirichlet kernel:
The lattice contains points, so it’s simple to evaluate the above and show that
We’ve found that is proportional to the identity matrix! Inverting it has become a walk in the park. That’s basically it. We just plug this into the KR estimator, finding
where the are the lattice coordinates. We’ve just recovered the well-known Dirichlet interpolant from kernel regression. In the aperiodic limit , this turns into the Whittaker-Shannon interpolation formula.
Concluding thoughts
Eigenlearning gives a theory of signal recovery from random finite samples. At its most powerful, it tells us what happens when we have insufficient data for perfect reconstruction, what happens when the learner is genuinely mis-specified with respect to the target signal, and how ridge regularization alleviates these.
Nyquist-Shannon is a special case: the signal is known to be low-dimensional and perfectly recoverable with enough samples and zero regularization. In exchange for this simplicity, we demand more: we want to be able to reconstruct the target signal efficiently (no kernel inverses permitted). To do this, we relinquish random sampling and instead use a regularly-spaced sampling lattice. This diagonalizes the regression estimator and exempts us from matrix inverse calculations. Neat trick, imo.
This learning/compression duality illustrates a fundamental tradeoff: the more we know a priori about the kinds of signals we want to learn, the fewer samples we’ll need to get high-fidelity reconstruction. It’s just no free lunch. For fixed kernels (as discussed in this post) the story is simple; for deep learning, where the kernels adapt to the data, the subtleties are only beginning to be understood.
Side quests
In eigenlearning, the average reconstruction error is given by eigenlearning as
Show that as , the average reconstruction error vanishes in the fully-specified setting (i.e., lies in the span of ). This demonstrates that as long as the target signal is entirely contained within the kernel’s RKHS, you will always be able to perfectly reconstruct the analog signal from any discrete samples (possibly excepting some measure-zero set of pathological samplings).
Using the convolution theorem, show that you can turn a passband signal (Fourier series has compact support in ) into a baseband signal (Fourier series has compact support in ) by pointwise multiplying the passband signal by . (Hint: convolving with a dirac delta is equivalent to a translating by .)
Using Eq. 1, show that the discrete Fourier transform of the Dirichlet kernel is a diagonal projection onto the low-frequency modes. (In this sense, the Dirichlet kernel is the time-domain representation of the low-pass filter on the unit circle.)